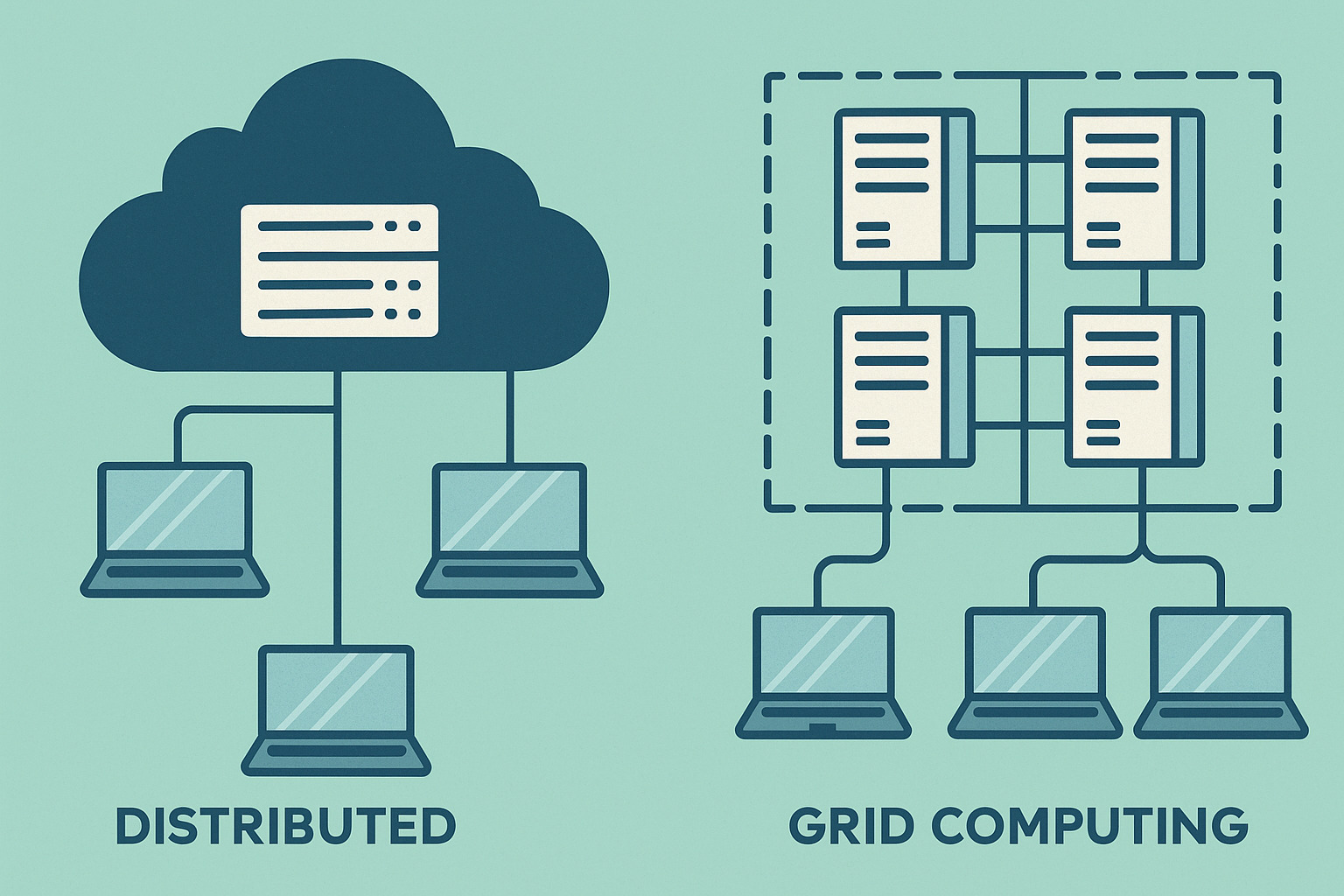
Understanding the Importance of Grid Computing
Grid computing is essential for organizations that need to process large volumes of data or perform complex operations. Instead of relying on a single powerful computer, tasks are divided across multiple nodes—smaller machines that work together. This approach results in faster execution and reduced costs.
It’s especially useful in sectors such as science, engineering, and business. Imagine a laboratory needing to analyze thousands of experiments; rather than processing them one by one, the workload can be distributed to dozens of nodes. This speeds up results and helps avoid bottlenecks.
In an era where information speed is crucial, grid computing serves as a strong backbone for large-scale projects. Efficient task distribution is not just about performance—it also helps ensure reliable, trustworthy outcomes.
How Nodes Function in Grid Computing
Each node in a grid computing system is an independent machine with its own CPU, memory, and storage. However, the real power of the grid lies in the connection among these nodes. A central coordinator or middleware determines which node has the available capacity and time to run a given task.
For example, if 100 files need to be encoded, there’s no need for a single server to process all of them. Instead, the 100 files can be split across 10 nodes, with each node processing 10 files. Once done, the nodes send back their results for a combined output.
Node efficiency depends on seamless communication and clear instructions from the controller. If one node fails, the system quickly finds a replacement so work can continue without interruption.
The Role of Middleware in Task Management
Middleware acts as the intermediary between the user and the nodes. It’s a software layer that decides which node will execute a task based on availability, load, and performance. Simply put, it’s the brain of grid computing operations.
Users don’t need to know which node is handling their task. They submit the job to the middleware, which automatically selects the most efficient route to complete it. It functions like a traffic controller, routing tasks to less-congested nodes.
The quality of the middleware has a direct effect on the overall grid. With good coordination, processes are fast and smooth. But if the middleware is overwhelmed or poorly managed, operations can slow down or stop altogether.
Load Balancing and Its Importance
One of the most critical aspects of grid computing is load balancing. The goal is to evenly distribute work so no single machine is overburdened while others sit idle. Balanced loads mean smoother operations and fewer disruptions.
Imagine having 50 tasks to complete within an hour. If you assign all the work to one node, it will be overwhelmed. But if tasks are evenly divided, performance improves, and issues like overheating or delays are minimized.
Load balancing depends on real-time monitoring. The system must instantly know which nodes are free or overloaded. This is where smart algorithms come into play, automatically adjusting the schedule based on node status.
Fault Tolerance in Case of System Failures
One of the main concerns in distributed systems is the failure of a component. But grid computing includes built-in fault tolerance mechanisms. This means that even if one node fails, the rest continue working.
Some systems automatically back up tasks. If a node becomes unresponsive, the task is reassigned to another available node. This concept also exists in cloud computing, but grid systems typically have more decentralized management.
Fault tolerance builds trust. Users don’t have to worry about losing progress or incomplete results. This is especially important in critical operations like financial modeling or scientific simulations.
Resource Sharing as the Core of Grid Efficiency
Grid computing is effective because it combines resources from various locations. Nodes may come from different cities or countries, but they unite to accomplish a shared goal. This is the essence of resource sharing.
For example, a university in Manila might have servers that are underutilized at night. Through grid computing, a research team in Cebu can use that idle capacity for urgent tasks. This ensures no resource goes to waste.
Such collaboration doesn’t just save electricity or hardware. It’s also a form of sustainable computing, making better use of existing infrastructure instead of always purchasing new equipment.
Data Management and Task Distribution Strategy
Effective grid computing relies on intelligent data distribution. It’s not enough to split tasks randomly. There must be a strategy that considers task size, priority, and time sensitivity.
Some jobs are better processed on nearby nodes to reduce latency. Others require high-security nodes for data protection. Overall, the task distribution strategy should align with project goals.
Good data management also aids in auditing, version control, and error tracing. If an issue arises, teams can easily track which node handled what, improving reliability and accountability.
Real-World Applications of Grid Computing
It’s not just tech companies that benefit from grid computing. Universities use it for weather prediction models, pharmaceutical companies for drug simulations, and animation studios for rendering films.
A great example is the Large Hadron Collider in Europe. Thousands of computers from around the world process physics experiment results simultaneously. This saves both time and money for the global scientific community.
Financial firms also rely on grid computing for risk analysis. Since they need real-time insights, they depend on real-time processing power—which grid systems efficiently provide.
Challenges in Implementing Grid Computing
Despite its benefits, grid computing faces challenges. The first is compatibility—not all machines have the same configuration, so extensive testing is needed to ensure everything works together.
Security is another concern. With many users sharing resources, it’s essential to prevent malware or unauthorized access. Encryption and authentication protocols are critical to maintaining system integrity.
Lastly, maintenance is key. More nodes mean more components to monitor and update. Teams managing grid environments need expertise in distributed systems and a strong commitment to uptime and performance.
A Resilient System for Future Growth
Grid computing proves that no single machine needs to carry the full load. Through collaboration among many devices, we gain a stronger, faster, and more reliable computing platform. It’s built on the principles of teamwork and smart distribution.
With the rise of IoT, machine learning, and big data analytics, grid computing is more relevant than ever. It’s the foundation of systems that demand speed and scalability. Understanding how workloads are distributed helps engineers, researchers, and businesses adapt to modern challenges.
Every successful run of a distributed task shows just how far technology can go when guided by coordination and efficiency.