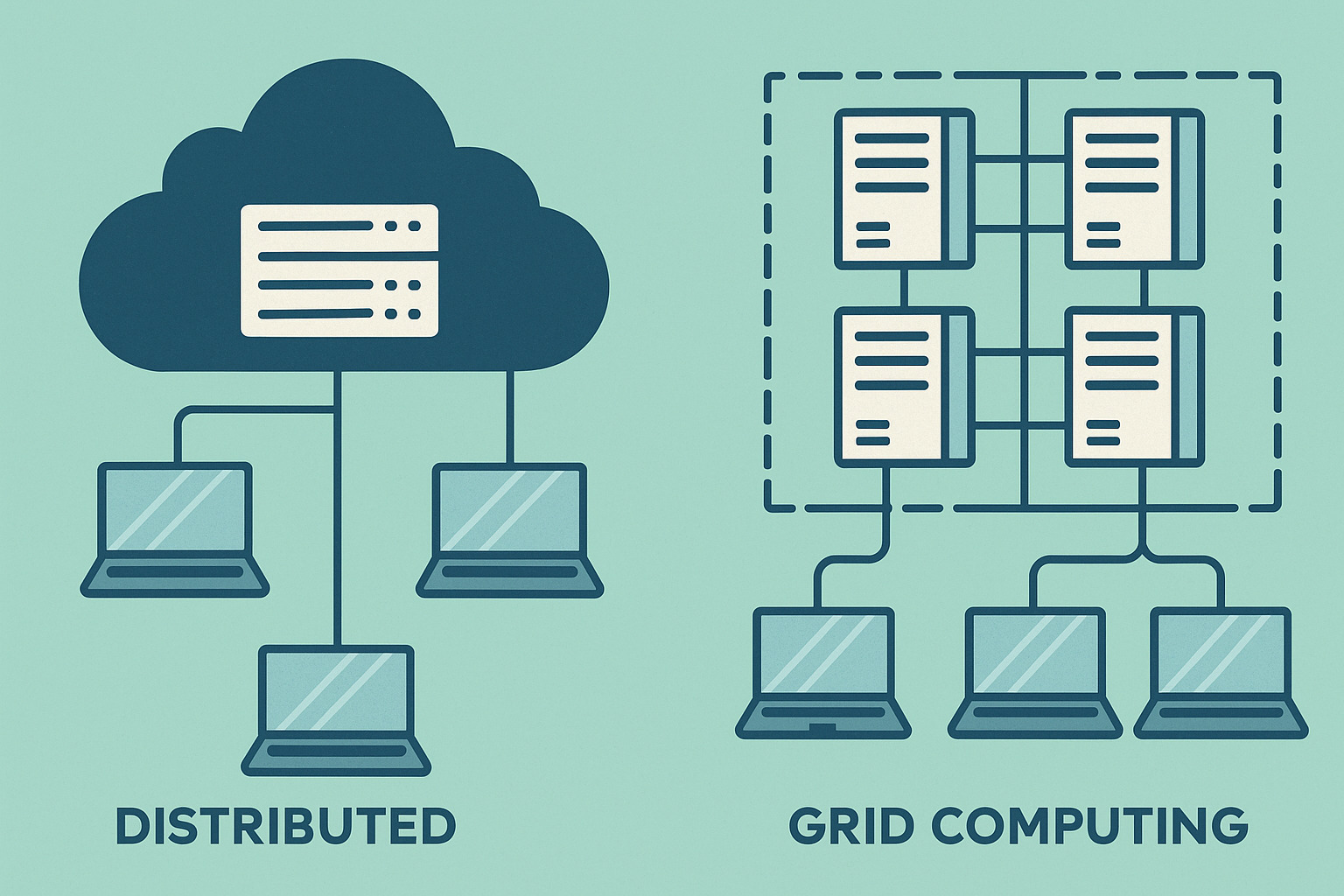
In the bustling world of grid computing, countless tasks from researchers, apps, and data pipelines arrive at a shared pool of computing resources. How do you decide which job to run next, how long to let it run, and which jobs might wait a little longer without causing chaos in the system? That decision making is the essence of job scheduling algorithms. Whether you are exploring how grids manage big data workloads or trying to squeeze the most performance out of your cluster, understanding these algorithms helps you design fair, efficient, and reliable compute environments.
What are job scheduling algorithms?
Job scheduling algorithms are a set of strategies used by a scheduler to decide the order and duration of job execution on a set of computing resources. The main goals are to maximize resource utilization, minimize waiting time, meet deadlines when possible, and keep users satisfied with reasonable response times. In grid computing, scheduling is often more complex than on a single machine because tasks originate from many users and may have varying priorities, sizes, and deadlines. A good algorithm balances throughput, fairness, and turnaround time across a distributed infrastructure.
Key concepts to know include:
– Arrival time: when a job enters the system.
– Burst time or CPU time: how long the job needs to run.
– Waiting time: how long a job sits in a queue before starting.
– Turnaround time: total time from arrival to completion.
– Preemption: the ability to interrupt a running job to start another.
As you dig into grid environments, you will also encounter terms like backfill, backfilling, preemption costs, aging, and quality of service (QoS) policies. These ideas influence which algorithm is a good fit for a given grid cluster or middleware layer.
Scheduling in operating systems and grid computing
Operating system (OS) schedulers manage processes on a single computer. In grid computing, scheduling spans multiple machines, clusters, and data centers. Grid schedulers must consider not only the estimated runtime of each job but also where the job can run most efficiently, data locality, network throughput, and policy constraints set by grid middleware. The transition from OS level scheduling to grid level scheduling brings new challenges such as heterogeneity of resources, variable queue loads, and the need for global or federated policy enforcement.
Operating System Scheduling Algorithms
These are classic policies that originated in OS design but form a useful baseline when discussing grid level scheduling. Each approach has advantages and tradeoffs in terms of fairness, efficiency, and complexity.
First Come First Served (FCFS)
- What it is: Jobs are executed in the order they arrive.
- Pros: Simple to implement; fair in terms of arrival order.
- Cons: Can lead to long average waiting times if a single long job blocks the queue; poor for interactive responsiveness.
In grid contexts, FCFS can be predictable but may underutilize resources if large tasks delay many smaller ones. It is rarely used as the sole policy in production grid environments, but it provides a straightforward baseline for understanding more advanced schemes.
Shortest Job First (SJF)
- What it is: Among the available jobs, run the one with the smallest estimated CPU time.
- Pros: Minimizes average waiting time for the set of jobs.
- Cons: Requires accurate knowledge of each job’s runtime, which is not always possible; can starve longer jobs if short jobs keep arriving.
In grid systems, estimating runtimes can be tricky. Heuristic estimates or historical data can help, but the risk of starvation for large tasks remains a concern, which is why SJF is often used in combination with other policies.
Round Robin Scheduling
- What it is: Each job gets a fixed time slice (quantum) in a rotating order.
- Pros: Good for interactive workloads; prevents any single job from monopolizing resources.
- Cons: Context switching overhead; if the quantum is too small, it can degrade throughput.
Round Robin is popular in multi-user environments where responsiveness matters. In grids, it can be used to ensure fairness among many small tasks while larger workloads run in the background.
Priority Scheduling
- What it is: Each job has a priority level; higher priority jobs run before lower priority ones.
- Pros: Aligns scheduling with user or application importance; effective for deadline sensitive tasks.
- Cons: Risk of starvation for low priority jobs; may require aging to keep the system fair.
Grid systems often implement priority with aging to prevent starvation. This allows long queues of low priority tasks to eventually run while high priority tasks still receive the attention they need.
Shortest Time Remaining (SRT) / Preemptive Shortest Job First
- What it is: A preemptive version of SJF. If a new job with a shorter remaining time arrives, the current job may be interrupted.
- Pros: Reduces average waiting time compared to non preemptive SJF; responsive for short tasks.
- Cons: Higher overhead due to frequent context switches; runtime estimates must be updated as a job progresses.
In grids, SRT-like policies can improve throughput for mixed workloads but require careful cost accounting for preemption.
Multilevel Feedback Queue (MLFQ)
- What it is: Multiple queues with different time quanta and promotion or demotion rules. Jobs can move between queues based on their observed behavior.
- Pros: Flexible and adaptive; handles diverse workloads well; balances responsiveness and throughput.
- Cons: More complex to configure; may require careful tuning to avoid starvation of certain classes.
MLFQ is a favorite for grid and HPC environments that handle a variety of job types, from short tasks to long simulations. It can adapt to changing workloads and preserve fairness.
Greedy algorithms in scheduling
A greedy approach makes locally optimal choices at each step with the hope of finding a global optimum. In the context of scheduling, a greedy policy might always pick the job with the smallest estimated remaining time or the highest priority at the moment. The appeal is simplicity and sometimes strong performance, but greedy methods can miss better long term results in a dynamic grid where workloads evolve, data moves, and user requirements shift.
In grid computing, greedy ideas are often embedded in more robust policies. For example, a greedy subroutine might select tasks that maximize immediate resource utilization, while higher level policies enforce fairness and SLA compliance. The key is to recognize that a single greedy rule rarely suffices for all grid scenarios.
Scheduling in grid middleware and systems
Grid computing relies on middleware to coordinate resources, data placement, and job dispatching. The scheduling layer interacts with resource managers, data transfer mechanisms, and policy engines. Here are some common players and concepts you are likely to encounter.
HTCondor style scheduling
- What it is: A flexible workload management system for built and dynamic HPC grids. It matches idle resources with pending jobs and supports complex policies.
- Scheduling aspects: Backfilling, priority classes, user quotas, job aging, and policy driven job routing to compute clusters.
Slurm
- What it is: An open source workload manager designed for large HPC clusters. It handles job submission, priority, and resource allocation.
- Scheduling aspects: Complex priority policies, backfill scheduling, and support for heterogeneous resources.
Grid Engine family (OGCE)
- What it is: A classic grid computing middleware for distributed resource management.
- Scheduling aspects: Queuing, resource quotas, and policy based dispatch across clusters.
Data and data locality considerations
- Data locality can drive scheduling decisions. Placing a job near the data it needs reduces network traffic and speeds up execution.
- In grids, data placement and compute placement are often coordinated by the scheduler to minimize data transfer costs.
How policies impact performance in grids
- Throughput vs latency: Some policies favor short tasks to maximize throughput, others focus on fast responses for interactive users.
- Fairness and QoS: Aging, quotas, and priority classes help ensure that long runs and time critical tasks get appropriate attention.
- Preemption costs: In distributed environments, preemption can incur data transfer and checkpoint costs, so its use should be balanced.
Evaluating scheduling policies for grids
Choosing an algorithm for a grid environment is not a one size fits all decision. It depends on workload characteristics, data locality, and policy constraints. Consider the following evaluation criteria:
- Throughput: Number of jobs completed per unit time.
- Average waiting time: How long jobs sit in queues before starting.
- Turnaround time: Time from arrival to completion.
- Fairness: Are users and groups treated equitably over time?
- Deadline compliance: How well the system meets job deadlines.
- Preemption overhead: The computational and data transfer cost when a running job is paused.
- Data locality impact: How scheduling decisions affect data movement and I O.
Practical steps to evaluate a grid scheduling policy:
1. Analyze the current workload mix by collecting historical data on job sizes, inter arrival times, and runtimes.
2. Run simulations or pilot deployments with different policies on a representative subset of the grid.
3. Measure key metrics (throughput, waiting time, tardiness) and compare against service level expectations.
4. Tune parameters such as time quanta, aging rates, and priority weights.
5. Iterate with adjustments to policy rules, backfill strategies, and data placement considerations.
Best practices for beginners in grid scheduling
- Start with a baseline: Use FCFS as a simple, predictable baseline to understand how queues behave.
- Move to policy diversity: Introduce priority levels with aging to prevent starvation.
- Use data to drive decisions: Gather historical runtimes and data transfer costs to improve estimates.
- Consider hybrid policies: Combine multiple strategies, for example a baseline priority policy with time constrained backfill.
- Embrace data locality: Favor scheduling decisions that minimize data movement where possible.
- Plan for preemption costs: If preemption is expensive, limit preemption to high priority tasks only.
- Monitor and adapt: Continuously monitor performance metrics and adjust policies as workloads evolve.
Real world examples and use cases
- Academic grids with mixed workloads: A university cluster runs many short scripts alongside long simulations. An MLFQ style policy helps keep students responsive while ensuring long running jobs eventually complete.
- Data science pipelines: Data prep, model training, and analysis jobs often have varying runtimes. A hybrid policy that prefers smaller, data-local tasks can reduce overall turnaround.
- Large scale HPC centers: Slurm based grids can enforce QoS classes for different groups and combine with backfill to maximize cluster utilization without delaying high priority tasks.
Practical tips for learners
- Practice with small workloads: Build a mini grid in a local lab or cloud environment to test scheduling policies.
- Use simulation tools: Student friendly simulators let you model FCFS, SJF, RR, and MLFQ with different workloads.
- Track metrics carefully: Keep a log of arrival times, runtimes, and completion times to compute waiting and turnaround times.
- Experiment with aging and backfill: See how policy changes affect fairness and utilization.
- Explore real world schedulers: Read documentation for HTCondor, Slurm, and Grid Engine to understand how policies are expressed in practice.
Frequently Asked Questions
What is FCFS in scheduling
It is the simplest policy where jobs are processed in the order they arrive. It is predictable but can be inefficient with long jobs delaying many shorter ones.
What is SJF in scheduling
Shortest Job First selects the job with the smallest estimated runtime. It minimizes mean waiting time but risks starving larger jobs.
What is preemption
Preemption means interrupting a running job to start another. It can improve responsiveness but adds overhead and costs in grid environments due to data context switching.
What is aging in scheduling
Aging gradually increases the priority of waiting jobs to prevent starvation. It helps ensure long jobs are eventually executed.
What is SRT or SRTF
Shortest Remaining Time First is a preemptive version of SJF. The scheduler interrupts the current job if a shorter one arrives.
What is multilevel feedback queue
MLFQ uses multiple queues with different time quanta and rules for promoting or demoting jobs. It adapts to workload mix and aims to balance throughput and responsiveness.
How do grid schedulers differ from OS schedulers
Grid schedulers coordinate many resources across clusters and data centers, consider data locality, data transfer costs, job deadlines, and policy rules. They often rely on middleware components and centralized or federated decision making.
Can I implement scheduling policies myself
Yes, especially in learning environments. Start with a simple queue model and gradually add preemption, aging, data locality, and backfill. Then compare the impact of each change on key metrics.
Resources and next steps
- Read the HTCondor and Slurm documentation to understand real world implementations of scheduling policies.
- Explore grid middleware tutorials to see how policy settings are applied to job submission and resource allocation.
- Look for case studies from grid computing projects that highlight how scheduling decisions influenced throughput and fairness.
- Try building a small grid test bed in a local lab or cloud environment to test different scheduling strategies and observe their effects in practice.
If you are exploring grid computing basics, this topic sits at the crossroads of theory and practice. Scheduling algorithms are not just academic concepts; they are the engines that drive the performance, fairness, and reliability of the grid you rely on for research, data analysis, and large scale simulations. By understanding the strengths and limitations of FCFS, SJF, RR, Priority, SRT, and MLFQ, you gain the insight to select or tailor policies that align with your workloads and your grid’s goals.
To continue your journey on grid computing basics, check out articles on middleware tools, batching strategies, and performance visualization that can help you observe how scheduling decisions translate into real world results on your grid.